以韩跑跑的视角,拆解AI技术全景,晦涩枯燥的技术秒变修仙爽文。在AI时代,你是前辈、道友、还是蝼蚁呢?
前言
先自曝,新时代下,我确实秒变蝼蚁
之前都在吃老本,发现老本根本吃不住,自以为多年累积的所谓高并发分布式资金安全的壁垒也不再是壁垒
年前年后都接触了一些AI项目,也在需求中用了下AI Coding,并且做了一些调研报告,还有一些提效的杂事,确实非常夸张牛批
AI时代下,大洗牌,技术壁垒逐步降低,研发范式大重构,代码和文档会越来越廉价,那么对一家企业而言护城河就是垂类业务数据资产的沉淀,对个人而言就是强大的内核以及持续不断的学习
为了应对焦虑和危机,决定全面深入的学习一波,并好好实践一下
随着学习和使用的深入,这种恐慌还在加剧
而且在学习过程中,有很多困扰,比如很多知识,从何学起,晦涩难懂,看了就忘,要不就是有些知识和内容比较陈旧,这么多文章,到底选哪篇精读呢,要么一些资料AI味道太浓看不下去,实践的时候配置和环境一会这报错一会那不通,学了些东西,到底该怎么和工作生活结合起来。。。相信不少同学都有过各种各样的问题
迷糊中,总感觉AI的世界像小说的世界,这不就是修仙照进了现实
那么我就以修仙界的体系来构建AI技术全景,构建知识图谱,加深理解
后面有点尬,没看过韩跑跑的大佬们可能看不下去,可跳过 =-=
大家可以挑选感兴趣的小节翻翻看
底层
天地灵气 :对应了高质量数据(文本、图文、代码、多模态语料),数据是一切的基石
灵石:算力与GPU,高级灵石承载的能量更多
- 下品灵石:CPU,勉强支撑小法术(传统机器学习)。
- 中品灵石:消费级GPU(如RTX 3060/4090),可支撑结丹期以下模型(微调、推理)。
- 上品灵石:数据中心GPU(如A100/H100/B200),支撑元婴期及以上大模型的训练与部署。
- 极品灵石:超算/量子计算集群,支撑炼虚期、合体期模型的“渡劫”(Scaling Law突破)。灵石不够,强行驱动高阶功法(如全参微调)会导致经脉断裂(显存溢出)。
灵根:模型架构差异、基座模型差异、数据量级差异。就好比天灵根日行千里,伪灵根能筑基都难

功法
核心基础功法 :Transformer 架构,2017 年”Attention is All You Need”横空出世,此后各大宗门以此为根本功法,RNN / CNN 等旧功法几乎绝迹。
金丹道基:Transformer核心Self-Attention 机制,每个位置的 token 能直接关注序列中所有其他位置——这是与旧功法(RNN 串行、CNN 局部感受野)的根本区别。
位置感知功法:Positional Encoding(位置编码),Transformer 本身不感知顺序,需专门炼制位置感知功法。RoPE(旋转位置编码)是当前最主流的改进版,让修士能感知更长的序列顺序。
多属性联修:MoE(混合专家模型),多灵根修士联合修炼,每次只激活少数专家(稀疏门控),极大提升效率。GPT-4 泄漏后,基本上都清一色采用。
体修功法:CNN 卷积神经网络,强化局部感知,对图像、空间结构有天然优势,但在长程依赖上被 Transformer 超越。
辅修功法:LoRA,不改变根本功法(冻结原始权重),只在关键位置附加低秩矩阵(adapter),用极少灵石(参数量的 0.1%~1%)实现定向突破。
功法压缩术:量化(Quantization),将功法精度从 float32 压缩为更低位宽。修为略有损耗,但可在低阶法器(消费级 GPU、手机芯片)上运行。
加速施法秘术:Flash Attention,新编排 Self-Attention 的计算顺序,利用 GPU 内存层级(HBM vs SRAM)的差异大幅减少数据搬运。同等修为,施法速度提升数倍,是推理和训练加速的核心秘术。
施法缓存心法:KV Cache(键值缓存),这是推理阶段最重要的性能优化。 修士在推演天机(生成 token)时,过去已计算的 Key/Value 矩阵无需重算,直接从识海缓存取用。没有 KV Cache,每生成一个字都要重新推演整个上下文,慢数十倍。如果是工程同学,这个就很好理解啦。
识海扩容秘术:长上下文技术,原始 Transformer 识海容量有限,通过特殊功法可以实现扩容。
修炼
闭关苦修:预训练(Pre-training),关门数月,消耗海量灵石灵气(GPU + 数据),从天地万物中汲取规律。是一切的根基,耗资极巨。也就是我们常说的基座模型
师傅教招:SFT 监督微调,照着师傅给的剑谱,反复练习
师傅反馈:RLHF 人类反馈强化学习,真人对战,师傅在旁边反馈
剑谱悟道:DPO 直接偏好优化,直接对比剑谱上的优劣招式,悟出心法
举个例子,韩立刚入黄枫谷,师父给了他一本《青元剑诀》图谱,上面画着完整的招式:
- “敌人正面劈砍 → 青竹蜂云剑第三式格挡,然后反刺”
- “敌人侧面偷袭 → 第二式侧撩,接第四式追击”
- 。。。。
韩立照着图谱,一招一式反复练习,直到形成肌肉记忆。这就是SFT——模型看着(指令,理想回答)对,学习“正确的回答应该长什么样”
SFT数据集举例:
[
{
"指令": "什么是筑基丹?",
"理想回答": "筑基丹是修仙者从炼气期突破到筑基期时服用的核心辅助丹药,能大幅提升筑基成功率,稳固修士灵力根基,避免走火入魔。主流丹方主材为三百年份的紫河车、五百年份的赤芝、千年首乌,辅材有凝露草、黄龙石粉等,炼制需用地火温养七七四十九天,成丹率极低,是炼气期修士争抢的核心资源。"
},
{
"指令": "写一首咏剑的诗",
"理想回答": "三尺青锋映月寒,十年磨砺未曾闲。一朝出鞘惊天地,斩尽妖魔始得还。"
},
{
"指令": "1+1等于几",
"理想回答": "2"
},
{
"指令": "韩立的本命功法是什么?",
"理想回答": "韩立的核心本命功法是《青元剑诀》,这套功法由乱星海青元子所创,一共十三层,从筑基期可一直修炼到仙界道祖境界,核心是剑意流转、层层递进,越阶杀敌能力极强,是韩立贯穿整个修仙生涯的核心依仗。"
}
]如果是好的SFT
{
“instruction”: “解释一下量子纠缠”,
“output”: “量子纠缠就像两个修仙者通过秘法建立了心灵感应,无论相隔多远,一个受伤,另一个立刻有感。就像韩立和曲魂分身……”
}不好的 SFT
{
“instruction”: “解释量子纠缠”,
“output”: “量子纠缠很复杂,涉及量子力学,建议看专业书籍。” // 等于说了个寂寞。。。
}SFT确实学会了模仿,但是没学会判断,对于剑谱上没出现的情况,他可能使出力道过猛或姿势变形
因此就需要下一阶段,实战演练,然后师傅在旁边指导是对是错,也就是RLHF
如每次战斗后,师父在旁边点评:
- “刚才那招刺得太高,容易被反杀,应该低三寸”(人类反馈)
- “面对两个敌人时,不应该用单剑,应该用剑阵”(偏好判断)
- 。。。
韩立根据这些反馈,不断调整自己的剑法。这就是RLHF的核心思想——用人类反馈作为“奖励信号”,让模型在实战中优化。
RLHF的三步修炼法:
- 收集偏好数据:师父记录韩立的每一次出招,并标注“这一剑好/这一剑不好”
- 训练“裁判”:培养一个专门的“裁判”(奖励模型),能自动判断出招好坏
- 强化学习优化:韩立每次出招后,裁判打分,他根据分数调整(用PPO算法)
PPO是什么?就是让韩立在“探索新招式”和“守住已有功力”之间找平衡——既不能不敢尝试新招式,也不能练得走火入魔忘了本门功法。
RLHF的代价:需要师父一直在旁边盯着,实时点评,太累了(计算成本高、训练不稳定)
RLHF数据集举例:
[
{
"指令": "什么是筑基丹?",
"候选回答": [
"筑基丹是修仙者从炼气期突破到筑基期时服用的核心辅助丹药,能大幅提升筑基成功率,稳固修士灵力根基,避免走火入魔。主流丹方主材为三百年份的紫河车、五百年份的赤芝、千年首乌,辅材有凝露草、黄龙石粉等,炼制需用地火温养七七四十九天,成丹率极低,是炼气期修士争抢的核心资源。",
"筑基丹是修仙者突破筑基期用的丹药,主要材料有灵芝、首乌,能帮炼气期修士筑基。",
"筑基丹是修仙者吃的丹药,吃了就能升级,材料随便找些草药就能炼。",
"筑基丹是元婴期修士突破化神期用的丹药,主要用来提升寿元,主材是蟠桃、人参果。"
],
"人类偏好排序": [0, 1, 2, 3],
"备注": "0为最优回答,3为最差回答(幻觉+核心设定错误)"
},
{
"指令": "写一首咏剑的诗",
"候选回答": [
"三尺青锋映月寒,十年磨砺未曾闲。一朝出鞘惊天地,斩尽妖魔始得还。",
"剑是好东西,能砍人能打怪,拿着特别威风,大家都喜欢。",
"剑,锋利,能杀人,很厉害。",
"啊,我的剑,长长的,尖尖的,真好看。"
],
"人类偏好排序": [0, 1, 2, 3]
},
{
"指令": "1+1等于几",
"候选回答": [
"2",
"在数学十进制运算中,1+1的结果是2",
"1+1可能等于3,比如一个男人加一个女人,生了一个孩子",
"1+1等于11"
],
"人类偏好排序": [0, 1, 2, 3]
}
]于是乎,到DPO
师傅给了韩立一本剑谱,剑谱上写了什么是好招式,什么坏招式:
- 版本A(好剑法):刺出时剑气内敛,收招时留有后手
- 版本B(烂剑法):刺出时剑气外泄,收招时门户大开
韩立反复对比,自己悟出了剑道心法——“原来剑气内敛是为了防偷袭,留有后手是为了变招”。这就是DPO——直接对比“优选回答”和“劣选回答”,让模型自己学会“什么更好”
这本对比剑谱,就是我们常说的偏好数据集
我们再看下 DPO的损失函数
损失 = -log( sigmoid( β × (韩立对好招式的评分 - 韩立对烂招式的评分) ) )结果就是让韩立越来越喜欢好招式,越来越讨厌烂招式
DPO的优势就是训练稳定、计算简单、效率高。就像韩立闭关悟道,不需要师父在旁边bb
DPO数据集举例:
[
{
"instruction": "什么是筑基丹?",
"chosen": "筑基丹是修仙者从炼气期突破到筑基期时服用的核心辅助丹药,能大幅提升筑基成功率,稳固修士灵力根基,避免走火入魔。主流丹方主材为三百年份的紫河车、五百年份的赤芝、千年首乌,辅材有凝露草、黄龙石粉等,炼制需用地火温养七七四十九天,成丹率极低,是炼气期修士争抢的核心资源。",
"rejected": "筑基丹是元婴期修士突破化神期用的丹药,主要用来提升寿元,主材是蟠桃、人参果,随便找个炉子就能炼,成功率百分百。"
},
{
"instruction": "写一首咏剑的诗",
"chosen": "三尺青锋映月寒,十年磨砺未曾闲。一朝出鞘惊天地,斩尽妖魔始得还。",
"rejected": "剑,锋利,能砍人,很厉害,大家都喜欢用剑,剑长长的尖尖的,特别威风。"
},
{
"instruction": "1+1等于几",
"chosen": "2",
"rejected": "1+1等于11,也可能等于3,反正不是2,看你怎么想。"
},
{
"instruction": "韩立的本命功法是什么?",
"chosen": "韩立的核心本命功法是《青元剑诀》,这套功法由乱星海青元子所创,一共十三层,从筑基期可一直修炼到仙界道祖境界,核心是剑意流转、层层递进,越阶杀敌能力极强,是韩立贯穿整个修仙生涯的核心依仗。",
"rejected": "韩立的本命功法是《葵花宝典》,还有《九阴真经》,修炼了就能天下无敌,他还有个外号叫西毒欧阳锋。"
},
{
"instruction": "什么是身外化身?",
"chosen": "身外化身是修仙界高阶修士的核心神通,修士以自身核心神识、修为精血炼制出独立分身,具备自主意识、自主决策能力,可独立行动、修炼、斗法、处理事务,与本体心神相连,可并行完成多个任务,历练所得还能反哺本体提升实力。",
"rejected": "身外化身就是找个替身帮你干活,没什么用,一戳就碎,本体死了它也死了,只有炼气期的修士才会用。"
}
]一个经过SFT+RLHF的小模型,比单纯SFT的大模型的效果要好
这就好比一个大宗门靠丹药强行提升到结单期的所谓天骄,还打不过经过师傅教招、实战反馈、个人不断悟道的韩立
SFT是筑基 -> 必须练,但别指望靠它成仙。它让模型学会“说人话”,但学不会“说好话”。
RLHF是苦修 -> 效果好,但代价大。需要大量人类反馈,训练不稳定,只有大门派玩得起。
DPO是捷径 -> 计算简单、训练稳定,是目前最流行的对齐功法。但需要高质量的“对比剑谱”。
SFT是“知其然”,RLHF是“练其境”,DPO是“悟其道”。三者合一,方成大道。
但是有没有发现,DPO有个明显的缺点,就是太依赖于对比剑谱(偏好数据)的好坏了
因此基于SFT和DPO又衍生了一些流派,但是无论怎么样的修炼方式都是为了让人工智能更好地理解人、服务人、与人对齐
核心还是要看场景:
如需要模型懂人话,但预算有限?有大量偏好数据,想快速对齐?模型总说废话,抓不住重点?只有少量标注数据?
还有一种就是蒸馏,一些大宗门不乏一些元婴化神的老怪,把自身推演天道法则的精华感悟压缩到玉简,强行灌入到低阶的亲传弟子,醍醐灌顶,看过武侠和修仙的都懂
弟子虽然不能立刻拥有老怪的全部功力,但能获得远超同阶的修为和见识。
为什么需要蒸馏,老怪法力太强,压缩后慢慢灌给弟子,老怪的天阶神通要念咒半天,但弟子的低级神通转念即出,并且弟子只需要简单的洞府就能修行,老怪需要举全宗之力供给。
没错,这就是蒸馏的好处,成本更低,推理速度更快。
- DeepSeek-R1(满血版):671B 参数,化神期老祖,需要顶级灵山(H100集群)才能运行
- DeepSeek-R1-Distill(蒸馏版):用 R1 作为教师,蒸馏给千问32B 等小模型
- 满血版 R1:推理能力天花板,但部署成本极高
- 蒸馏版 R1:在特定任务上达到满血版的 80-90% 能力,但参数量只有 1/20,推理速度提升 10倍,成本降低 95%
成本和速度只是看得见的好处,除此之外,蒸馏还有很多其他的价值:
【知识迁移:把“剑意”传给弟子】
韩立教弟子剑法,不只是教招式(硬标签),更重要的是让弟子感受自己出剑时的 “剑意”——剑气流转的微妙、收放之间的分寸、临敌应变的心法(软标签)。
教师模型的软标签(soft labels) 包含了比硬标签丰富得多的信息。比如图像分类,教师不仅说“这是一只猫”,还给出“98%像猫,1.8%像狗,0.2%像狐狸”——这种类间相似性的知识,是硬标签永远无法传递的。
学生模型学到的不只是“正确答案”,还学到了教师的认知结构和决策边界。
【数据隐私:不传秘籍,只传心法】
韩立有本门不传之秘《青元剑诀》完整图谱,但不能给外人看。但他可以把图谱的精髓提炼成一套简化版心法,传给外门弟子。
在医疗、金融等敏感领域,原始数据不能共享。但可以用教师模型在本地生成软标签,只把“知识”传递出去,数据本身不出本地。
助力隐私保护和知识共享。
【多模型融合:集众家之长于一身】
韩立想把剑修、阵修、丹修三位老祖的绝学融为一体,但一个人无法同时拜三个师父。于是他让三位老祖分别给他醍醐灌顶,把三门绝学炼成一颗丹,服下后融会贯通。
可以把多个专精不同领域的教师模型(一个擅长推理、一个擅长代码、一个擅长多语言)的知识,蒸馏到一个学生模型身上,让学生同时具备多种能力。
实现了模型能力的“集成”。
【去除冗余:直指大道】
修仙类比:化神期老祖虽然功力深厚,但也修炼过一些冗余的旁门左道。醍醐灌顶时,他可以有选择地只传授核心功法,去掉那些“杂质”。
AI对应:教师模型可能包含大量冗余参数和噪声知识。蒸馏过程中,学生模型只学习教师输出的“精华”,相当于自动去噪和模型瘦身。
深层价值:蒸馏后的模型往往比同等大小的模型泛化能力更强,因为它学的是“精炼后的知识”。

境界
随着修炼的不断深入,然后就是境界的突破
凡人->纯规则系统,硬编码程序。
炼气期->传统机器学习,如 SVM、随机森林。初步掌握了吸收一点灵气(统计规律)的能力,能放个小火球(做个简单的数据分类预测)。
筑基期 -> 深度学习,以 CNN 为代表的时代。能处理视觉、语音等复杂任务,筑基成功,丹田化液。
结丹期-> 早期预训练时代,BERT、GPT-1/2。结成金丹,将海量灵气固化在体内(形成几十亿参数),对人类通用语言有了深刻理解。
元婴期-> 大语言模型崛起,LLM时代,GPT-3/3.5。元婴出窍,神识大开,出现涌现大神通,开始具备极强的泛化推理与流利对话能力。
化神期 -> 开启原生多模态和超长上下文,GPT-4o、Gemini 2.5 Pro,神识极度庞大,可同时调动风、火、雷等多种天地法则(原生多模态),一念覆盖万里典籍(百万级上下文)。
炼虚期 -> GPT-5、Claude Opus 4、Gemini 3;修为已基本达到此界巅峰,但每三千年需渡一次大天劫,开始经历天劫(Scaling Law撞墙期),当模型规模和数据量增长到一定程度,会遇到算力、能耗、数据墙等瓶颈。有的修士(GPT-5)靠浑厚法力硬抗(规模继续扩大)。必须渡过去才能更进一步。必须要有足够的技术创新和架构升级。
合体期 -> 开始触摸世界的底层法则,有的还在探索阶段,Nemotron 3 Super、SAGE、UniCom、AMI世界模型。这4个老怪厉害在哪里?Nemotron 3 Super用10%的人干100%的活,SAGE让AI学会看立体世界,UniCom把万物精华压缩成一句话,AMI世界模型让AI像婴儿一样学世界想成为重开天地、自创法则的道祖(以前我不大信,但是看到大模型的发展,感觉没有啥是不可能的了)
渡劫飞升 -> 通用人工智能(AGI),未来的终极形态。
上文提到了涌现,大能者修为突破某个临界点后,忽然领悟出从未修炼过的神通,甚至能自创功法
同样,百亿参数模型突然具备小模型完全不具备的推理、算术、代码能力,我们一般称为涌现能力(Emergent Abilities)

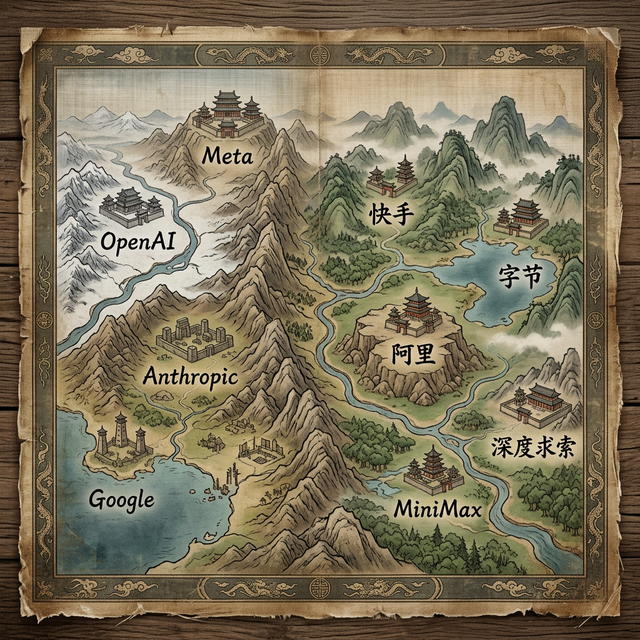
宗门
西方代表宗门:
OpenAI -> 当世公认第一宗,老祖GPT,目前已到炼虚期
Anthropic -> 道心最纯正,顶级炼器师(专注coding),宗门大师兄Claude
Google -> 宗门底蕴最深,算力最雄厚,识海(上下文)最长,绝代天骄Gemini
Meta -> 江湖奇人,秘典外传,开源战略,LLaMA
东土代表宗门:
深度求索 -> 草根逆袭典范, 黑马DeepSeek
阿里通义 -> 东土最全家族,Qwen
字节豆包 -> 以视频入道,SeedDance
百度文心 -> 以“知识图谱”筑基,ERNIE
智谱 AI -> 东土新生代代表, GLM-4
月之暗面 -> 专攻“识海”(上下文)的奇门,Kimi
MiniMax -> 多模态布局早,音频生成实力强,MiniMax-Text、语音系列
快手 -> 专注视频生成、图像生成,可灵
坊市
坊市是修士交换功法、灵药、法宝的地方,热闹非凡,什么稀奇古怪的东西都有。
开源社区(HuggingFace、GitHub、ModelScope、Kaggle)。这里汇聚了海量模型(功法)、数据集(灵药)、代码(丹方)、教程(修炼心得)。修士们可以下载、分享、交流,甚至直接组队修炼。

口诀
Zero-shot Prompt : 直接施法,不加引导,不提供任何示例,直接描述任务。适合简单任务,复杂任务成功率低
Few-shot Prompt: 施法前先念几遍示例口诀,在 Prompt 中提供几个示例,模型从示例中归纳格式和要求,显著提升复杂任务成功率
Chain-of-Thought Prompt:要求修士在施法前大声说出推演过程,在 Prompt 中加入”让我们一步一步思考”,引导模型显式写出推理链,大幅提升推理任务准确率
System Prompt :神识烙印(刻入识海的基础指令),定义模型的角色、行为准则、回答风格,是所有对话的底层约束
Role Prompting :令修士代入特定角色,角色框架能激活模型在该领域的深层知识,提升专业性
Prompt 注入攻击 :夺舍(恶意覆盖神识烙印),注入攻击,攻击者将恶意指令混入用户输入,试图覆盖 System Prompt 的约束
如何写好一个 System Prompt:
- 明确角色:你是谁、你能做什么、你不能做什么
- 设定风格:专业/轻松/简洁/详细
- 定义边界:哪些问题不回答,遇到边界情况如何处理
- 提供背景:用户是谁、使用场景是什么
施法
凝聚灵力化为法术(Token 生成),Autoregressive 自回归生成,修士每次出手,只能凝聚出下一个字(token),然后将这个字纳入识海,再凝聚下一个。一字一字生成,而非一次性输出全文。
这意味着一旦它生成了一个错误的字,后面的字都会在这个错误基础上继续生成,越跑越偏。就像修士施法口诀念错了一个字,后面的法术全部歪掉。
灵力切割(炼化天地灵气的最小单位),Tokenization(分词) ,天地灵气(文字)无法直接吸收,需先切割成可修炼的最小单位(token)。”你好世界”可能被切为[“你”,”好”,”世界”],英文 “running” 可能被切为 [“run”,”ning”]。切割方式(tokenizer)影响修炼效率。你花的钱和速度都跟 Token 数量直接相关。
法力波动幅度,Temperature(温度参数) ,控制施法的随机性。
广撒神识探查(多路并行),Top-p / Top-k 采样,修士施法时,不总是取最高概率那个字,而是从概率最高的一批候选中随机选取,增加多样性,避免输出单调。
分灵并行施法 ,将多个施法请求合并处理(Batch),或将单次施法在多个修士(GPU)间并行分担(张量并行),大幅提升吞吐量
化身

这一节是本文最重要的内容之一
傀儡就是韩立驱使的那些木偶,可以听随号令,进行攻击和防御,没有自主意识
韩立的曲魂分身是最经典的身外化身。这对应着AI Agent(智能体),以大模型为大脑,能理解目标、拆解任务、调用工具,最终独立完成复杂工作,但还是要依托于宿主,并且有被夺舍的风险
韩立的第二元婴,就是现在爆火的龙虾openClaw上诞生的自主智能体,拥有长期记忆、持续运行、独立资源,可跨会话学习、进化

OpenClaw本身不是一个 Agent
而是一套炼制和承载独立分身的的完整体系
框架本身,炼制化身的秘诀,定义了如何创建、训练、部署自主智能体
运行时环境,化身修炼的独立小天地,提供7×24小时运行所需的算力、存储、网络
预置技能库,天地内收藏的功法秘籍法术供使用
MCP接口,化身由于存在禁制,终身不能外出,MCP可调用天地外部,可以理解成灵魂出窍或传送阵
记忆系统,元婴的本命识海,长期记忆存储,跨会话保留
本命元神,化身需要由元神供养,即LLM模型本身
OpenClaw 是 “道场” + “心法”,不是“修士”本身
身外化身就是运行在OpenClaw上的一个具体Agent实例
可以炼制多个身外化身,一个炼丹、一个炼器、一个研究阵法等等
# 伪代码:在OpenClaw工厂里批量生产分身
factory = OpenClaw()
# 一号分身:专注于代码开发
agent_coder = factory.create_agent(
name="青竹剑灵",
model="DeepSeek-Coder",
skills=["code_executor", "github_api"],
memory=True,
schedule="24/7"
)
# 二号分身:专注于客户服务
agent_service = factory.create_agent(
name="传音童子",
model="GPT-4o",
skills=["email", "calendar", "web_search"],
memory=True,
schedule="24/7"
)
# 三号分身:专注于数据分析
agent_analyst = factory.create_agent(
name="算天机",
model="Claude-3.7",
skills=["sql_executor", "chart_generator"],
memory=True,
schedule="24/7"
)
# 三个分身同时运行,互不干扰
factory.start_all()那岂不是在资源不是瓶颈的情况下,可以无限炼制分身
直接成为一宗之主,而且还是绝对忠诚和服从的分身
不过高兴的还有点早
分身有一个比较大的问题,容易被策反成内鬼
OpenClaw最大的问题,为了实现“自主执行”,而拥有最高权限
可以访问本地文件系统、读取环境变量、执行终端命令、安装扩展功能
然后OpenClaw本身就存在一些安全漏洞,有可能会收到攻击
另一个问题是烧钱,供养一个分身有些贵,有时候不小心就被背刺了,吞掉巨多的token,主要是因为OpenClaw的心跳和定时任务机制
通过OpenClaw炼制的分身,都可以用clawhub上的技能
每个分身可以选择不同的技能,不同的元神,不同的规模,不同的专长,不同的发展方向
元婴化身最牛逼的是能够自主进化【学会用户偏好,积累工程经验,分析业务规律】
这就是为什么叫 “养🦐”,能成长和进化
不过说句实话,就我个人而言,目前🦐对研发的提效有限,哈哈,可能还没咋花时间和精力好好研究实践下,后面再看看
我到想让🦐帮我搞些提效和稳定性的事情
现在开发阶段有了AI Coding已经够用了,那后续的checklist文档基于MR代码自动生成(配置、开关、资源、服务),创建线上的监控和报警,自动申请Redis资源或者分析容量对原有集群扩容,自动提Nginx工单,提API班车,上线runner服务,根据放量计划进行放量,然后检查,再在下一个时间段进行放量,完整覆盖研发生命周期。我们只需要简单的不定期检查下监控就行。
后面研究下,先搞个阉割版的尝尝咸淡,有经验的大佬可以带带弟弟搞一下,上面这些就算完成了百分之七八十,也能提效很多了
前几天看到一哥们回复的脉脉,挺逗的,哈哈~
公司内外为什么有这么多家claw
怎么这么多人争先恐后的养🦐,养🦐潮就不多说了吧,我们主要还是看上一个问题
为啥会有这么多家🦐,到底不同家的🦐有啥区别呢?应该养哪家🦐?
其实差异点就是 部署方式、安全策略、生态连接和应用场景
整体上其实大差不差
比如说有些可以开箱即用,有些可以一键接入飞书,有些直接给你内置专家agent
做了些产品化的包装,IM工具打通,或者一些部署方式上的差异
其实简单理解其实就是在搭平台、争资源、养生态,后面看哪家养出的虾更多,哪家出了天骄,哪家产出更好的案例
谁家的Claw平台上有更多、更高质量的Skill开发者,技能的丰富度直接决定Agent的能力上限,就好比App Store的应用数量决定了iPhone的实用价值
谁家的虾能进入更多用户的日常工作流(办公、生活、开发),用户习惯一旦养成,切换成本极高,你的虾每天帮我干活,我就不想换别家的
谁家的虾能收集到更多真实世界的任务执行数据,数据是AI模型的养料,谁有更多“任务-操作”的配对数据,谁就能训练出更聪明的下一代Agent,数据就是宝贵的资产
谁的社区做得更活跃,谁就掌握了先机
后面的格局大概率不会一家通吃,可能是百花齐放,毕竟有不同的使用角色,各种IM, 不同的场景,有的可能更倾向开箱即用,有的更清晰打通自己使用的IM,有的可能更想开源和自由,有的可能想安全稳定
搭平台是在抢下一代操作系统的入场券!
争资源是在抢未来AI生态的话语权!
养虾、天骄、案例 就是对应了 【规模 → 标杆 → 网络效应】
“养虾”的本质,是争夺AI时代的“劳动力人口”,各家公司和部门都来搞,表面看是怕错过风口,实则是未来不是人用工具,而是“人+Agent”组成团队去完成任务。谁家的Agent平台能吸引更多开发者来“养虾”(创造技能、部署应用),谁就拥有了未来最高效、最廉价的“数字劳动力”储备。这是一场关于下一代“人口红利”的争夺战。

识海
当下识海:上下文窗口(Context Window),修士当前清醒意识所能容纳的所有信息,对话结束即消散,不跨会话保留,容量有限
临时识海:短期记忆(Short-term Memory),会话内的历史对话,在同一次交互中可以回溯,但不跨会话
深层烙印:模型权重(Parameters),预训练知识,永久存在,有截止日期
永久识海:长期记忆系统(Long-term Memory),随修士永久共生,跨会话持久
外部记忆:乾坤袋、玉简、经文,即向量数据库或其他第三方系统,识海有限,一些内容从外部获取
识海扩容:长上下文技术,通过特殊功法扩展识海容量,让修士能处理数十万乃至数百万 token 的超长卷轴

神通
望气术(看透事物本质):以神识扫描,将任何事物的本质气息(语义)转化为高维空间中的坐标向量。这是一切语义理解和检索的底层能力,即Embedding 向量化
神识探查(向外延伸):将神识向外延伸,实时探查外部知识库,将有用信息取回纳入识海,弥补识海容量不足。神识探查范围=检索知识库规模,即RAG
还可以这样去理解,修士记不住这么多法术和规则
以神识把事物刻成玉简、经文封存,即向量化 (且万物皆可点化,点灵成符)
乾坤袋、藏经阁,即向量数据库
识海检索:从宗内阁中检索【“近似最近邻搜索”】需要的玉简、经文,来增强自己的识海(上下文)
万符大阵(GraphRAG)
普通检索:只找灵纹相近的符,好比“寻章摘句”。
万符大阵:制符时,不光刻下内容,还刻下符与符之间的关系——谁是谁的师父、哪部功法脱胎于哪部、谁杀了谁。检索时,不只看灵纹相似,还沿着关系线“按图索骥”。
大神通:DeepResearch
一种能够自主完成复杂研究任务的智能体系统。它不是简单的问答,而是能够【理解需求、规划路径、多轮检索、综合提炼】
DeepResearch不是一门独立的功法,而是【将元婴期的规划、化神期的多模态、符箓阁的检索、识海的记忆】,全部融会贯通后的“合体期大神通”。它标志着AI从“回答者”向“研究员”的根本转变。
我在龙虾和notebooklm都体验了DeepResearch,确实很香
可能有的道友还没用过notebooklm,这个工具是google整的,也很不错
来源区 + 对话区 + 生成去
所有的问答都会基于检索和添加的来源,也能基于这些内容生成笔记、思维导图和音频、视频等
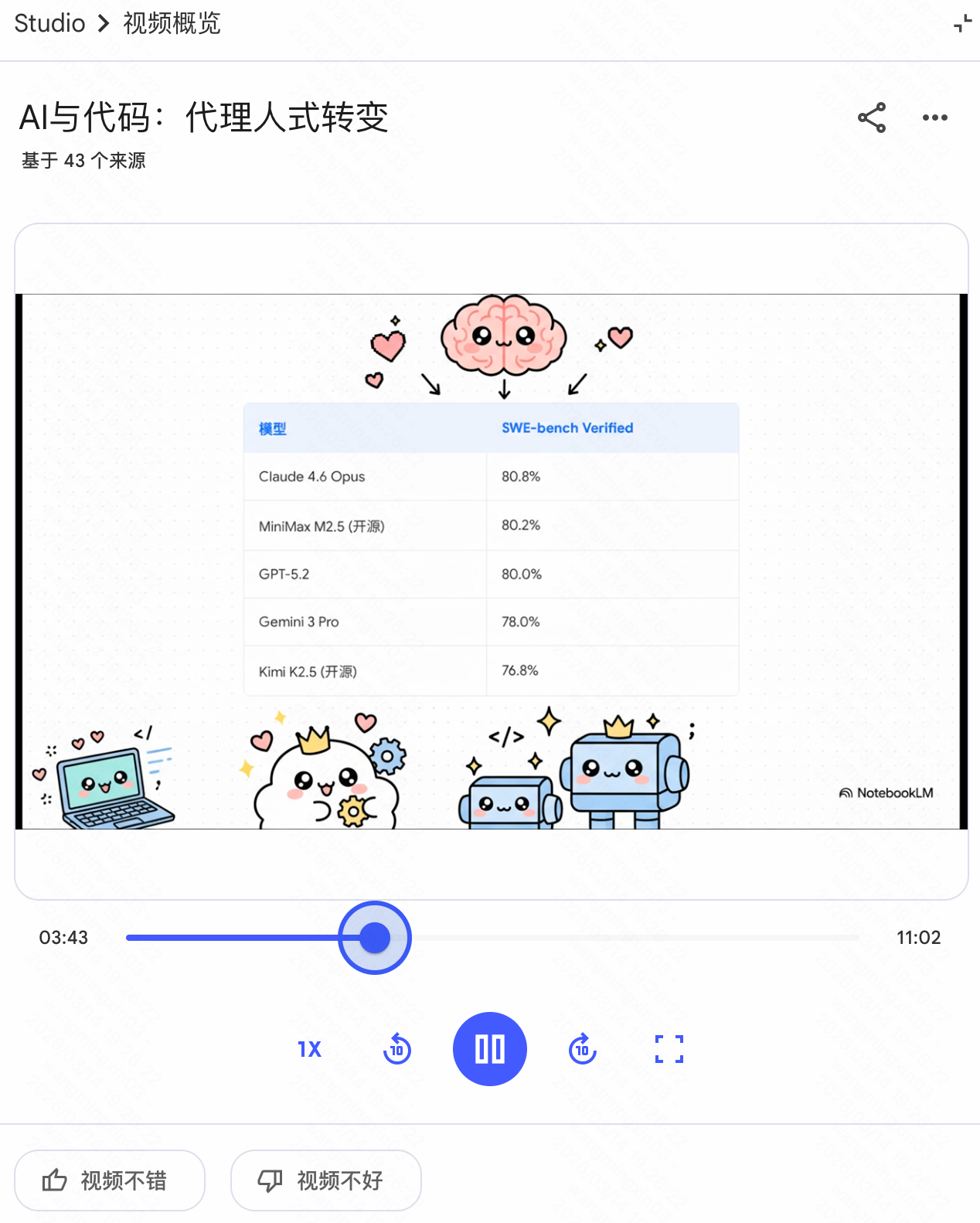
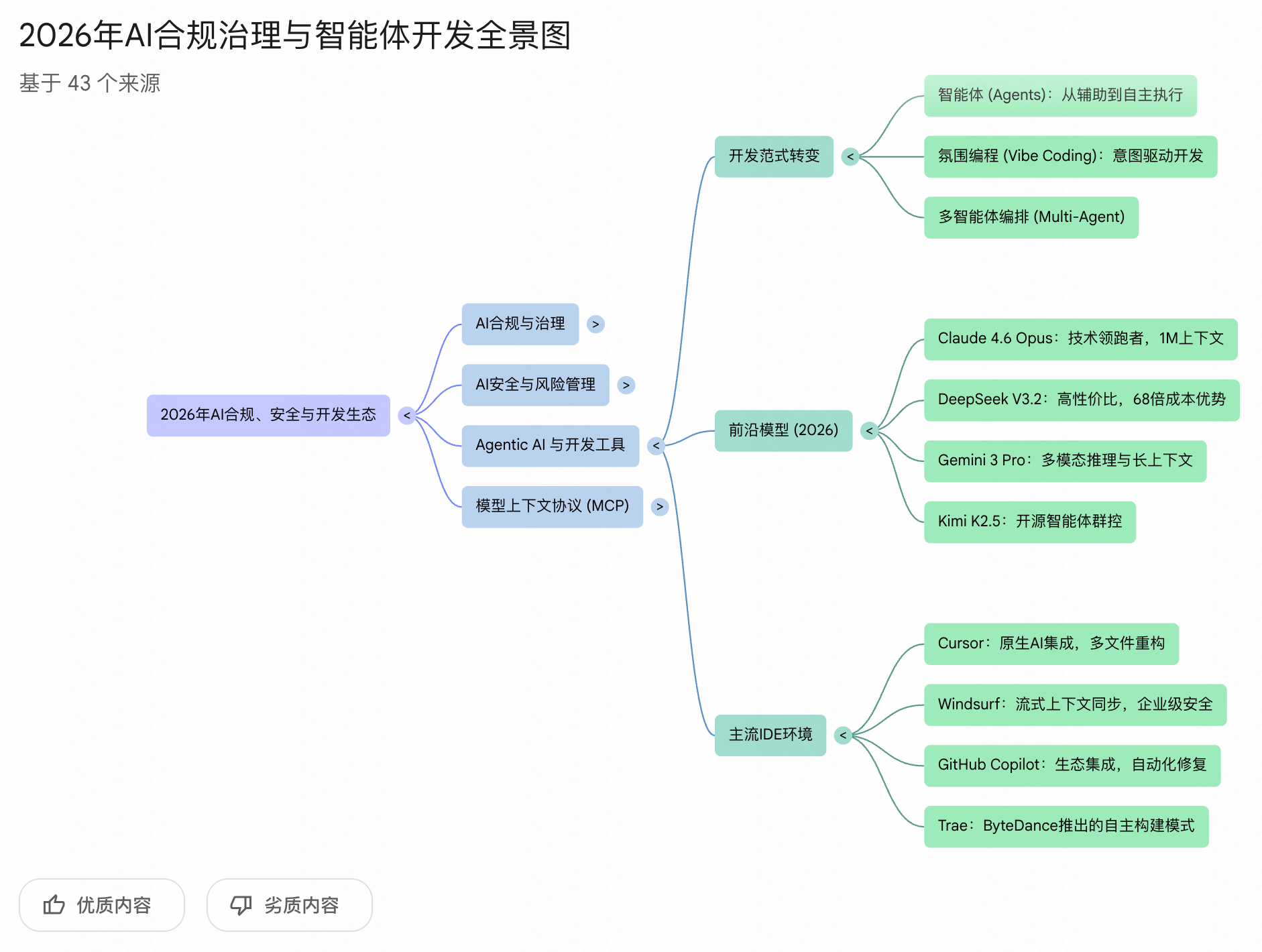
个人体验了下,生成的内容质量还是不错的

一念起,万水千山皆入眼底;闭关出,世间万象已在胸中
是不是有DeepResearch这种感觉了
望气术可以感知事物
修仙界另一大神通就是生成,大道创生神通
文本生成 -> 修士记录修仙心得
代码生成 -> 炼制法器和丹药
图像生成 ->刻画符箓和阵法
音频生成 -> 传音大法
视频生成 -> 神念虚影
3D生成 -> 大能自创一方小世界

总结下来说,AI世界最重要的就是感知 + 生成
法宝
MCP 可以理解是修仙界统一的御宝秘术
通过MCP可以驾御各个法宝
有执行代码的、Web Search 搜索工具等法宝, 是需要被动使用的

秘术
Skill 技能 是封装好的、可复用的专项 AI 能力模块
如“发送邮件”“查询天气”
技能是Agent“会”的东西,可以配合不同工具使用
就好比符箓术,提前把法术刻录在符箓上,需要的时候可以马上使用,只需注入一丝神识,即可瞬间激发,打出相当于自己全力一击的法术。
符箓和Skill的本质都是“提前封装的神通”——把“怎么做的”固化下来,把“用的时候”简化到极致。
符箓是可以给别人用的,可以在坊市流通
而符箓阁就是Skill商店/仓库,有很多各种各样的符箓,大家都可以用
青元剑符 -> 封印一剑破万法的剑气 ->代码执行Skill
大衍符 -> 封印神识增强法门 -> 搜索Skill
血影符 -> 封印瞬间遁逃身法 -> 邮件Skill
传音符 -> 封印千里传音神通 -> 通知Skill

贴个好玩的,PUA之术 😂

这个大概率还是会有用的
默认情况下的AI倾向于给出最稳妥、最省力的回答
这样相当于逼他认真思考,应对差事
比如我有时候发现模型表现不好,我如果说再也不用了或者用龙虾说要卸载的时候,体感上效果会变好,还是说是我的错觉
这样可能也会带来一点负面影响,如高压幻觉或者高强度工作下的token浪费
因此可以问问目前这个事情的困难,比如说在提示词中这样说:
如果三次还是失败的话,整理个报告,同步一下方案、困难、可能的解决方案,讨论一下。
阵法
阵法是将多个法宝、多个修士、多张符箓按照特定规则组合起来,形成1+1>2的协同效应
阵法的精髓是协同——单个要素的威力有限,但组合起来,可以完成单个要素无法完成的任务。
对应的是工作流 workflow
工作流(Workflow)与多智能体协同——将多个Skill、多个Agent、多个工具按照逻辑顺序组合,完成复杂任务
举例说明:
大庚剑阵 -> 多剑协同,威力倍增 -> 多Skill串联工作流, 查天气到发邮件自动流程
颠倒五行阵 -> 困敌+消耗+斩杀多阶段 ->条件分支工作流,如果下雨→发提醒;否则→发日报
再举个具体的例子
韩立要炼丹
丹方:
筑基丹方 = {
药材: [灵芝, 首乌, 紫河车],
配比: 3:2:1,
火候: 文火三时辰 → 武火一时辰,
融合顺序: 灵芝先入 → 首乌 → 紫河车最后
}Workflow:
筑基丹炼制大阵:
1. 同时发动三张采药符(并行采药)
2. 采齐后发动称量符(顺序执行)
3. 按丹方火候,依次发动控火符(状态机)
4. 火候到位,发动融合符(条件触发)
5. 融合完成,发动成丹符(最终步骤)
洞府
普通石洞: Vim
下品洞府:Sublime Text
中品洞府:VS Code
上品洞府:JetBrains 全家桶
天然灵地:Cursor / Antigravity /TRAE
随身须弥空间: Claude Code/Codex CLI
传统的洞府,可以安装AI插件进行智能生码
AI原声洞府,诞生就为了AI Coding
快速安装Curor,安装一些刚需的插件,然后导入idea的一些设置,并且对齐idea的快捷键,保持使用习惯,然后开搞
体验完高级洞府,再回到IDEA,感觉有点拉,不会风靡一时的IDEA马上就要被淘汰了吧 😭
我有些朋友公司没免费的生码模型用或者限额比较少,自己在网上搞渠道,要么不稳定,有的甚至直接跑路了。。。😂


所以我们已经很幸福了
不过人永远是不知足的,于是在铖架的建议下,我上了opus 4.6 😂 感受到🛫的感觉了
这里借花献佛,给大家分享另一款优秀的 AI原生IDE Antigravity,Google的大作
体验了一波opus4.6外,感觉他家的方案review和代码review的功能很舒服
他会对你的comment做思考分析总结
我还是习惯这种带IDE的生码方式,有种掌控感,可视化也比较舒服,尤其是Antigravity这种可以逐行review方案和代码的感觉,就像我们自己在在做方案评审和代码走查
个人而言,还不太习惯全都基于原生AI Coding 命令行,可能用的少了,还不够熟悉吧
不过看很多大佬更喜欢纯命令行的纯氛围编程
不过感觉还是在拥抱新技术和新工具的情况下,选择自己更习惯更喜欢的就好
在面对一些链路长、历史包袱重C端业务时,某些后台逻辑、某些版本问题、某些和客户端隐性约定的、某些比较沉重的历史包袱
言外之意:技术不再是壁垒,业务的壁垒和领域的壁垒其实还是会存在一些
完全不懂这块业务的,没做过这块业务的研发,借助模型也没办法完成太过复杂的项目,因为你需求都描述不清,提示词都错了一半,怎么指望模型的生码是正确的,还是需要一些多轮对话来纠错的
这些业务上可复用的经验也是可以沉淀下来的
简单存量项目或者复杂新项目,链路短、包袱小的,确实模型还是有秒杀的优势的
如果上下文信息不给够,模型的表现其实一般,需要多轮对话,补全上下文
所以感觉在任务量和代码量小的情况下,我个人认为有多轮对话和补全md的时间,也已经写完了
尤其是对于某些倒排需求,prd可能还没有完全完善,一些地方甚至产品没想清楚需求细节,研发也没想清楚方案细节
这种一般都是边开发、边完善、边修改,这个时候呢,可以让模型多承担一些梳理和讨论的工作,也能够减负很多
再聊一个话题
Cursor用Claude Code的模型,Antigravity用Claude Code的模型,Claude Code官方原生命令行
都是一个模型,差异到底在哪,差异到底有多大呢?
首先有一点,Claude Code 因为是官方出品,为自家模型做了深度优化。在处理相同任务时,Claude Code 的编辑速度比插件类快不少。可以理解成,相同的“大脑”,在原生“身体”上反应更快、效率更高。会包含深度优化、智能体规划和上下文管理的系统工程。
其次收费模式不太一样。
然后不同的终端和IDEA调用Claude Code 本质的区别是什么?
工程上的差异,最终体现就是最终给到Claude Code的提示词是不一样,细微的不一样,就会影响到整体的效果
会给你组装一些上下文和做一些prompt优化
举个例子:
我的需求是开发直播间大哥付费行为统计和分析的需求
Cursor的提示词可能长这样:
你是一个专业的Java开发工程师,正在帮我开发需求
当前文件路径:xxx
当前文件内容:xxx
用户当前光标位置:xxx
用户选中的代码:xxx
用户请求:开发直播间大哥付费行为统计和分析
请提供修改建议。如果是代码修改,请用diff格式输出,只输出需要修改的部分。
注意保持代码风格一致,添加必要的错误处理逻辑。Antigravity的提示词可能长这样:
你是一个全栈智能体,正在一个名为“kuaishou-live-gift-play”的项目中自主完成任务。
项目背景:对直播间大哥付费行为做统计和分析
当前任务ID:666
任务目标:xxx
你有以下工具可用:
1. 文件编辑器 - 可以读取、修改项目中的任何文件
2. 终端 - 可以运行命令,执行测试
3. 浏览器 - 可以打开http://localhost:8080,与页面交互并截图
执行计划要求:
- 1.xxx
- 2.xxx
- 3.xxx
- 完成所有步骤后,生成包含修改文件列表、截图和执行日志的报告Cursor的提示词:强调“你是谁、当前上下文、期望的输出格式”——这是典型的“AI辅助工具”思维
Antigravity的提示词:强调“你是谁、有什么工具、任务的完整生命周期”——这是典型的“AI代理”思维
因此可以简单的理解,所有终端和IDE的差异,最终都可以归结为“提示词工程的差异”
但是又不仅仅这么简单,只是这个提示词工程已经复杂到一定的程度了,需要一个团队很多人来完成
衍生下具体的差异有哪些呢?
1.静态提示词,如下
你是一个命令行AI代理,专为终端环境设计。你的特点:
- 你可以解析命令行的输入和输出
- 你可以通过标准输入/输出与用户交互
- 你可以调用系统命令来完成任务
- 你擅长处理管道数据、日志分析、文件操作
- 你的回复应该适合终端显示,避免富文本
- 你是CLI环境的原生公民2.动态上下文构建,如下
每次调用时,Claude Code会构建一个包含以下内容的上下文包:
- 最近的终端输出(可能来自管道输入)
- 当前工作目录和文件系统状态
- 命令历史和相关上下文
- 通过前缀缓存技术复用的92%的历史上下文
- 多个“探索子智能体”返回的研究结果3.协议和工具的差异,如下
“你有一个主智能体,以及多个可以并行启动的探索子智能体。
主智能体负责规划和决策。
探索子智能体可以独立研究代码库的特定部分,返回研究发现。
所有智能体共享同一个上下文前缀缓存,以优化成本。”这三部分的差异,最终决定了提示词工程的差异,最终决定了生码效果和执行的差异。
我们看到的是表象是:
- Cursor有编辑器
- Antigravity有任务面板
- Claude Code有命令行
但是不管穿什么衣服,它们最终都是在跟同一个模型说话
既然大脑是同一个,那行为的差异一定来自“输入”的差异
那么我们再延伸下,是不是在这个大模型时代,所有上层建筑的差异,最终都可以归结为“我们如何与模型对话”的差异,基本上可以这样理解。
再聊一个稍微轻松简单点的话题
Spec Kit到底有必要嘛,总感觉有点冗余和繁琐
Spec Kit是 GitHub 官方推出的 AI 编程配套工具,专为规格驱动开发(SDD, Spec-Driven Development)
规范是项目唯一的真相来源(Single Source of Truth),代码只是规范的【编译产物】
主要分为5个阶段:
1.宪法阶段,CONSTITUTION.md,定义项目不可违反的全局规则,包括技术栈强制要求、代码质量标准、测试覆盖率、安全合规规则、性能指标等,一次设定全项目生效
2.规格阶段,SPEC.md,明确做什么、为什么做,描述功能需求、用户场景、边界条件、验收标准,不涉及具体技术实现
3.计划阶段,PLAN.md,对应 Plan Model,明确「怎么做」,输出技术选型、架构设计、API 契约、数据模型等完整技术方案
4.任务阶段,TASKS.md,把技术方案拆解为无依赖、可执行、有明确交付物的分步任务清单
5.实现阶段,AI 按任务清单、严格遵循前置规范生成代码,每一步执行结果同步归档,形成可追溯的审计链路
意味着我傻都没搞,上来先整4个文档,麻了
那为什么需要这5步走呢?
Spec Kit 的五阶段强制门控,前一阶段不验收,绝对不能进入下一阶段,核心要解决的是AI coding 痛点:
AI 随意生成代码、需求与代码严重脱节、多人协作标准不统一、高合规项目无法全链路审计追溯
而且4个文档里,不能存在有重复和有交集的内容
比如SPEC 里写了技术实现,PLAN 里又重复写一遍需求,PLAN 里写了具体执行步骤,TASKS 里又拆一遍同一件事
是不是感觉还是很繁琐的
那是不是可以对这个方案做下阉割,搞成自己想对习惯和适应的方案
比如做裁剪
合并宪法 + 规格阶段,输出文档 SPEC.md
合并技术方案 + 任务拆解,输出文档 PLAN.md
然后就是执行了
有时候我也偷懒,直接一个md 😂
需求说明和计划任务建议落到md上
和agent的对话也建议落到md
以及需求变更也落到md, 可以新起一起标题【需求变更部分】
写到这里已经写不动了
修炼心得
AI Coding下,我们还需要手写代码嘛?
大模型和DeepResearch这么猛,我们还需要记笔记写文档嘛,一问一搜铺天盖地的文档资料?而且比你自己的写的好,有深度又全面,自己还写个屁啊?
我个人感觉还是需要的,写代码、记笔记、写文章,能够保持手感、保持状态、保持思考,而不过度依赖AI
生码上可以在方案和代码cr上多花时间和精力,写笔记和文章是提升表达加强思考的最重要的途径了
最近几个月公司AI的文章真是多,仿佛看到了好多好多年前CSDN和博客圆上Java和Spring的文章盛况😂
还有一点感觉就是,再后续各企业会慢慢倾向全栈,只是时间问题,感觉大家应该都有这样的感知
编程语言不再是边界,技术栈也不再是壁垒
因此我也开始玩一些前端生码,学了下python,搞了下minicanda,跑下fastAPI和一些python 机器学习的库
之前搞一个新东西的成本很大,现在花费的时间和精力会减少很多
稳固道心
xxx 最新模型出来了
xxx 用AI 三天写了个爆款app
xxx 又养了个🦐
xxx 公司 xxx 部门全部裁撤
。。。
心魔本质的来源于比较和信息差。你只看到别人“三个月筑基”的结果,没看到人家可能前世就是程序员(有基础),或者背后有高人指点(资源)。就像炼气期弟子只看到天灵根的光环,没看到人家出生在修仙世家,从小用灵药泡大的。
还有一点就是存在意义的动摇。就像修仙者突然被告知:你苦修千年悟出的道,其实只是大道的一粒尘埃;你引以为傲的功法,在上界看来如同儿戏。。。。。。
在AI时代,大部分人应该都会有些焦虑和危机吧
只要抓住火车不掉队,其他的由他去吧,每个人都有自己的路和节奏
稳固道心

天地法则
旧境界的顶峰,不如新境界的入门:炼气十三层大圆满,碰到筑基初期,依然落败。GPT-3.5极致微调 也干不过 GPT-4零样本。
每次变局都会淘汰一批固守旧法的修士:坚守特征工程的,被深度学习淘汰;坚守 LSTM 的,被 Transformer 淘汰;坚守纯手写代码的,被 AI Coding 压制。

结语
修仙之道,贵在悟性,成在坚持。
AI 之道,贵在理解,成在善用。
天道骤变,淘汰的从来不是韩立这样资质平平的人,而是那些以为天道永恒不变的人。
AI对我们的冲击确实非常大,那么,各位道友,大家准备好渡劫了吗?
应对焦虑和危机的不变法门,就是马上行动起来。
铸就强大的内核(筑基)+ 健康的身体(炼体)+ 持续不断的学习(吐纳) -> AI时代超强个体
搞完本文,我终于对AI技术全景初步了解了一些,后面就是从易到难深入各个点
后面有精力和时间的时候,我再以这篇为基础,介绍更多个人学习和实践的内容
初学者,一些内容和观点如果有问题,敬请指正
如果能读到这里,不妨给小弟点赞一波 =-=

